CTINEXUS
Automatic Cyber Threat Intelligence Knowledge Graph Construction Using Large Language Models
CTINexus is a novel framework that automatically transforms unstructured cyber threat intelligence into a rich, connected cybersecurity knowledge graph (CSKG). By leveraging in-context learning with large language models, it extracts relevant cybersecurity entities and their relationships from threat reports—without requiring extensive labeled data or specialized rule sets. CTINexus adapts quickly to new and evolving threats, consolidates information through hierarchical entity alignment, and infers hidden links among distant parts of a report to build comprehensive, high-quality cybersecurity knowledge graphs for more effective threat monitoring and analysis.
News:
System Overview
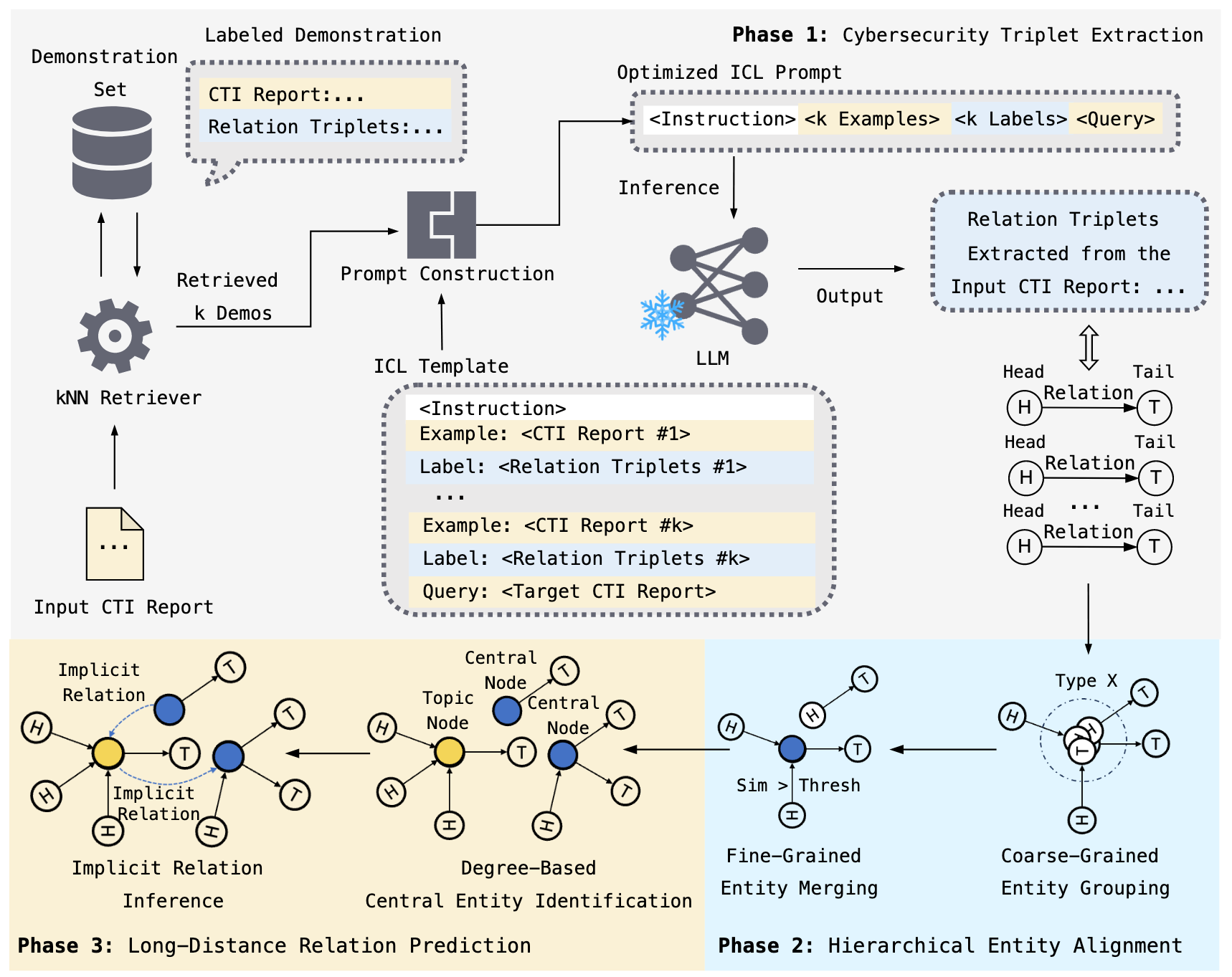
Comparation with baselines
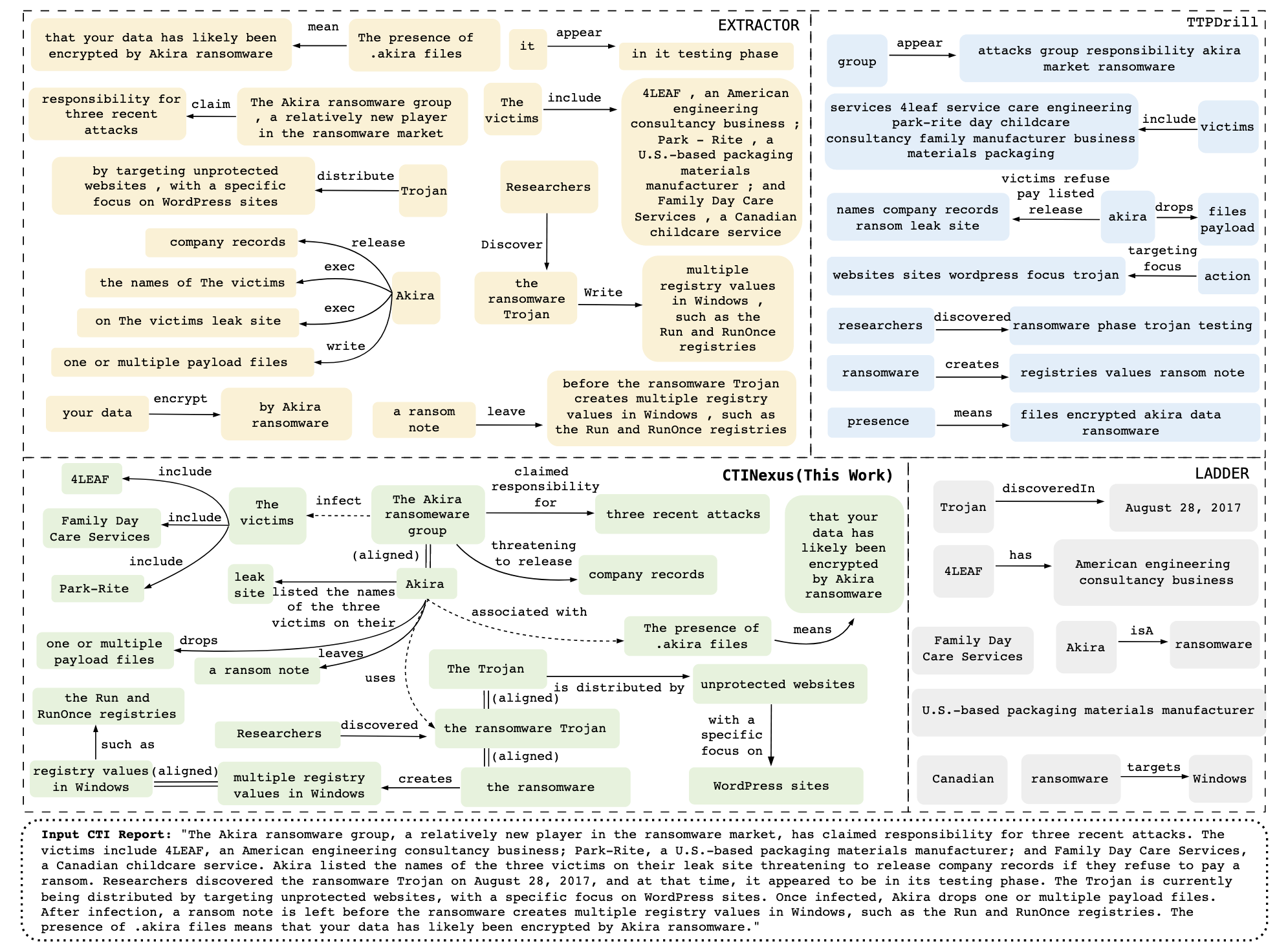
Takeaways
Citation
@inproceedings{cheng2025ctinexusautomaticcyberthreat, title={CTINexus: Automatic Cyber Threat Intelligence Knowledge Graph Construction Using Large Language Models}, author={Yutong Cheng and Osama Bajaber and Saimon Amanuel Tsegai and Dawn Song and Peng Gao }, booktitle={2025 IEEE European Symposium on Security and Privacy (EuroS\&P)}, year={2025} }